MotionMatching
Motion Matching
现代动画技术中,Motion Matching是个绕不开的话题。为了解决动画过渡自然和真实性,动画系统从传统Locomotion状态机到混合节点,到Pose Matching、Motion Matching,从最初的特征向量基础到现在的ML/DL/RL的混合式变种。近年也很多GDC都有详细的介绍各种工程落地:
- Reinforcement Learning Based Character Locomotion in Hitman: Absolution (GDC2013) - by Michael Buttner
- Motion Matching and The Road to Next Gen Animation (GDC2016) - by Simon Clavet
- Animation Bootcamp: Motion Matching: The Future of Games Animation (GDC2016) by Kristjan Zadziuk
- From Motion Matching to Motion Synthesis, and All the Hurdles In Between (GDC2019) by Fabio Zinno
- Ragdoll Motion Matching (GDC2020) by Simon Clavet
- Motion Matching in ‘The Last of Us Part II’ (GDC2021) by Michal Mach, Maksym Zhuravlov
- Take ‘CONTROL’ of Animation (GDC2021) - by Ilkka Kuusela, Ville Ruusutie
- Environmental and Motion Matched Interactions; ‘Madden’, ‘FIFA’ and Beyond! (GDC2021) by Henry Allen
- Machine Learning Summit: AI Animator : A Real Time Motion Completion System (GDC2022) by Yinglin Duan
- Controlled Chaos: The Combat of ‘Marvel’s Guardians of the Galaxy’ (GDC2022) by Rodrigo Barros Lima, Olivier Tremblay-Ross
- Motion Matching at EA: Five Years Later (GDC2023) by JC Delannoy
- Technical Animation Pipeline of ‘Fort Solis’ (GDC2024) by Matthew Lake
- MotorNerve: A Character Animation System Using Machine Learning (GDC2024) by Songnan Li, Yuchen Liao
Reinforcement Learning Based Character Locomotion in Hitman: Absolution
这个视频是2013年游戏开发者大会(GDC)的一个演讲,由Michael Buttner主讲。这是GDC最早讲述Motion Matching类似的技术原理,或者说是技术雏形,此视频极有观看价值。传统游戏角色移动系统通常依赖“手动混合树”和大量游戏代码来控制和微调动画(如从走路到奔跑的过渡)。这些方法效率低下,尤其在处理复杂场景时(如人群中的AI角色)。Buttner分享了他们在《杀手:赦免》中采用的一种新型方法,使用强化学习来自动化和优化Crowd的动画和移动。数据驱动是这个技术的核心,视频是把其称为Motion Graph,或者是Pose Matching,主要是应用到了其Crowd中(当年玩杀手系列的海量可交互Crowd确实震撼)。

上图是简单表述这个技术的关键思想(Key Idea)
给定一定数量的动画,我们需要通过识别匹配的姿势来找到可能的过渡。
构建一个有向图(directed graph),其中边对应于运动的片段(fragments of motion)。
Motion Graph同时其描述了四个跟传统动画节点的特点:
自动检测匹配姿势:Motion Graph 通过自动识别相似姿势生成过渡,避免手动规则,确保动画自然流畅。
基于物理属性的控制器逻辑:系统依赖动画数据的物理特性(如速度、角度)构建逻辑,实现更真实的运动模拟。
无需特定动画知识:控制器不需预知动画细节,仅靠数据搜索和匹配,简化扩展和维护。
数据驱动系统:以动画数据为导向而非规则,提升灵活性和可扩展性,自动优化质量。

上图展示动画帧的差异度量。这是一个度量函数,用于计算两个动画帧(如A_i和B_j)之间的“不相似度”D(A_i, B_j)。在Motion Matching中,不相似度越低,意味着两个帧越匹配,越适合作为过渡点。在构建Motion Graph时,系统需要扫描大量动画数据,找出相似部分来创建边(transitions)。这个度量就是“相似性判断器”,确保过渡自然,避免动画“跳跃”或不协调。D(A_i, B_j)是“不相似度分数”,用于比较动画序列A中的第i帧和序列B中的第j帧。分数越高,两个帧越不相似(e.g., 角色姿势差异大);分数越低,越可能匹配。
不是单看一帧,而是取一个“窗口”(比如前后几帧),将它们转化为“点云”(point clouds)——一种3D点集合,代表角色关节的位置(如肩膀、膝盖等关键点在空间中的坐标)。动画是连续的,单帧匹配容易忽略上下文。通过窗口点云,系统能捕捉运动趋势(e.g., 角色在加速还是减速),让匹配更准确、更动态。同时度量中加入了“导数信息”(derivative information),即速度、加速度等变化率(数学上,导数表示)。这意味着不只比较静态位置,还考虑动态因素(如关节移动的速度)。
最终分数是“加权平方距离和”。对应点(e.g., A帧的左手点 vs B帧的左手点)计算欧几里得距离,然后加权求和(权重可能根据关节重要性调整,如腿部权重高于手指)。

上图是一个“误差函数”,通过采样方式计算两个动画序列中所有帧对的误差,形成一个2D表面(像热力图)。误差最低的点(局部最小值)被视为“良好过渡点”。图片中展示了示例动画序列(如“WalkFTurnR135”可能指“走路前转右135度”,“Idle-WalkRF”指“从idle到走路右前”),并用灰度图像表示误差函数:深色区域表示低误差(好匹配),浅色表示高误差(差匹配)。
系统对两个动画序列(如A和B)的每一对帧(e.g., A的第i帧 vs B的第j帧)计算误差,使用之前提到的Dissimilarity Metric(不相似度)。这些误差值组合成一个2D函数(像一个网格或表面图),x轴和y轴分别代表两个序列的帧索引。图片中的灰度图像就是这个2D函数的采样表示。左侧是“WalkFTurnR135 vs WalkFTurn180”的误差图,右侧是“Idle-WalkRF vs WalkFTurnR135”。深色斑点表示低误差区域(帧对高度匹配),形成“山谷”状的局部最小值。这不是简单的一对一比较,而是全面扫描所有可能配对,形成一个可优化的“误差景观”。在游戏中,这能快速定位最佳过渡,而不需要手动检查成千上万的帧。
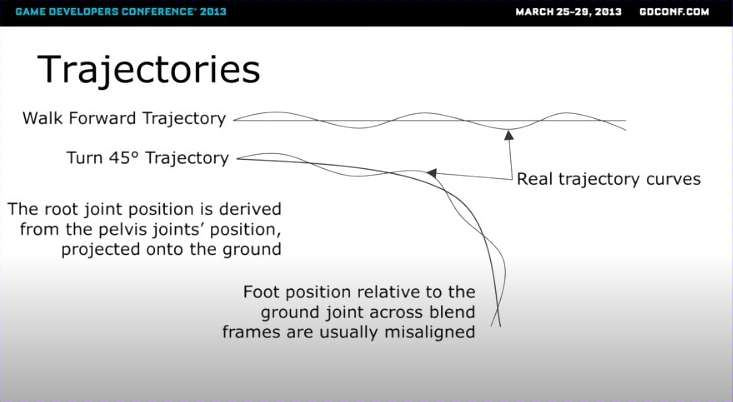
上图中“轨迹”指的是角色根关节(root joint,通常是骨盆/pelvis)的运动路径随时间的变化曲线。它不是简单的直线,而是基于动画片段计算出来的“预测路径”,比如角色往前走、转弯或跳跃时的预期路线。轨迹是从骨盆位置“投影”(projected)到地面上得来的。简单说,就是把角色的“腰部运动”简化成地面上的2D曲线,用于规划脚部如何踩实地面、避免滑动或碰撞。
当混合不同动画帧时,脚部位置往往“错位”(misaligned)。比如,直走轨迹和转弯轨迹对接不上,导致角色在转弯时脚滑或姿势扭曲。这直接就是严重的滑步问题(可参考原视频的演示动画)——轨迹不对齐,根运动就乱套。
轨迹是从骨盆位置投影到地面的,但动画混合时忽略了脚部与地面的动态互动。例如:角色在平地直走时轨迹平滑,但转45°时,如果不调整脚踏点,投影后的曲线就会“跳跃”或弯曲不自然。这在非均匀地面(坡道、楼梯)或变速运动(从慢走到快跑)中更明显。结果是“脚部位置跨帧不对齐”,造成视觉 bug 如滑动、抖动或不协调。最常规的做法是用IK解决,像UE5中的实现,如果有更大余量,生成并匹配最优预测轨迹的动画肯定是最好的。
本演讲有额外的名词:Blend Pivot。混合导致滑步核心问题是标准混合是对“动画层次结构根节点周围的“局部变换”(如位置、旋转)进行插值。它像“围绕根节点”均匀混合前后动画,导致整个身体的运动都以根节点为中心渐变。结果是,混合看起来平滑,但往往忽略了具体关节的世界位置,容易造成整体偏移或滑动(比如脚在地面滑行)。即使姿势匹配,脚的位置可能在混合过程中“滑”开,因为标准混合没锁定脚的世界坐标,只管根节点的局部变化。这直接导致之前的“脚滑”和轨迹错位。Blend Pivot 允许在过渡混合期间,保持某个特定关节的世界空间位置不变,通过“偏移”其中一个混合姿势,让目标关节的世界位置与对应姿势匹配。通常选脚踝(foot joint)作为枢轴,以防脚滑;或选手部关节,用于互动动画(如抓取物体)。添加偏移计算(e.g., 计算枢轴的世界位置差,然后应用逆变换到根节点),同时结合 IK进一步微调。
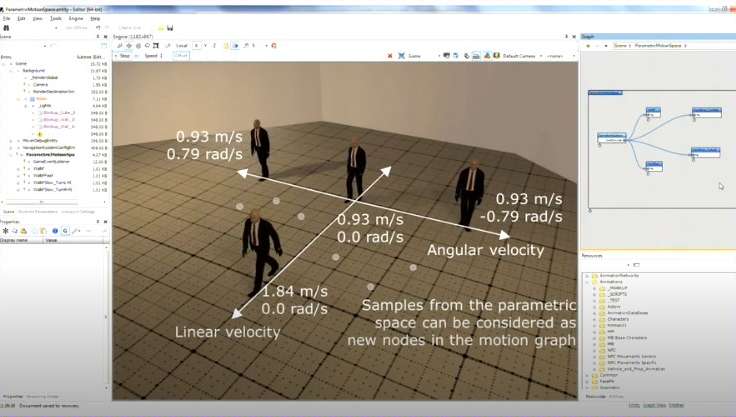
上图是展示演讲的概念:参数空间(Parametric Space)。通过参数混合不同转弯动画(e.g., 轻转 vs. 急转),让角色更快响应输入,而非等待完整片段结束。这是Pose Matching的根据,展示了混合如何让转弯更快、更自然,而非生硬切换片段,并避免了之前轨迹错位的问题。
前几张聚焦“如何生成和混合动画”(e.g., 参数空间采样创建新节点、轨迹匹配避免脚滑、速度参数驱动转弯)。这张图承认这些技术解决了“连续性”问题,但引入新挑战:图变复杂后,如何高效“挑选”片段序列?例如,速度采样(线性/角速度)生成了无数新节点,但怎么选(e.g., 高角速度时,优先哪条转弯路径?)。如 Looping/Non-Looping 片段或 Blend Pivot:这些是图的“建材”,但剩余问题是“怎么用建材建路”——需要智能算法导航,避免死路。

然后是经典的强化学习,马可夫决策过程(MDP)。上图就是经典的贝尔曼方程,演讲里杀手的Pose Matching是通过MDP不断学习,状态定义x = (θ, φ) ∈ S,让 θ (偏差角度)向 趋近 0, C(速度) 接近 φ,即把方向纠正,速度纠。强化学习理论是相通的,熟悉的可以直接跳过,这里也不赘述了。
Cost成本函数(对于RL就是负奖励函数): \(c_s(X) = γ_θ θ + γ_φ Δφ\)
- X:当前状态(和前面定义的状态向量一致,可理解为 X = (θ, φ, …))
- θ:偏差角度(当前朝向与目标朝向的差)
- Δφ:速度偏差(当前速度与期望速度 φ 的差的绝对值)
- γ_θ, γ_φ:权重系数,控制两种偏差对总成本的影响占比
然后就是应用策略,这里就是计算所有最简单的贪心策略——遍历所有当前transition,取最低Cost(最高),可以说是跟Q-Learning十分的像了。后面也讲到最优策略——累计所有未来*折扣因子的Cost,取其最小值。相对于贪心策略,最优策略不是只看眼前,而是权衡“即时成本”(当下决策的代价)和“未来所有决策的成本”(长远影响)。然后还是Q-Learning的试错逼近和基函数逼近(常用的就是神经网络了)。
演讲最后强调了几点:
- 这个框架可用于许多不同任务:这里的“框架”指整个 RL + MDP + 成本系统的组合(前文从状态定义到最优策略)。它不只限于“角色移动”(locomotion,如转弯/速度匹配),还能扩展到其他动画问题(e.g., 战斗姿态、跳跃、交互物体)。
- 任务定义需要一些实验:定义 RL 任务不是一蹴而就,得通过试错调整(e.g., 改状态向量、调成本权重)。意思是:别指望公式一写就好,得在引擎里反复测试,观察动画效果(转弯是否自然)。
- 响应性随可用动画数量扩展:系统的“灵敏度”(e.g., 对玩家输入的快速反应)取决于你有多少预备动画片段(e.g., 运动图中的节点)。动画多(结合参数采样),响应就快;动画少,系统就卡顿。这提醒:RL 不是魔法,得有丰富的基础数据支持。
- 它不是要取代状态机或混合树,而是实现它们:RL 不是“推倒重来”,而是“升级版”——它可以内部实现状态机(用策略模拟状态切换)或混合树( 用成本评估混合权重)。或者说Motion Graph(Motion Matching)不是完全替代现有动画状态机的手段,而是扩展。可以说这作者的理论和落地当时都十分先进了。
Motion Matching and The Road to Next-Gen Animation
这应该是Motion Matching影响力最的的一个演讲了。Simon Clavet还被投资媒体称为Motion Matching之父。本编是把Motion Matching落地于《For Honor》这款强调精准中世纪战斗的游戏,玩过这游戏都觉得这动画的丝滑度比现在大部分游戏都好。演讲主要涵盖几个知识点:动画系统历史回顾、Motion Matching技术的核心和工作流程管线与实现。
动画系统历史回顾是个开场缓冲,Hitman的演讲也有。Motion Graph和Motion Field上面演讲也讲过。演讲前半部分没有讲很深入的东西,有一部分讲到《For Honor》的Mocap的dance card:

分别是Turn On spot、Interrupted Start、Reposition(没有转动的位移)、Starts/Stops、Circles、Plants45/135、Plants90/180(指“脚部植入”或“固定着地”的动作,常用于描述转身、停止或改变方向时脚部的固定姿态)、Strafe Square、Strafe Plants 180。
然后是讲述MM的运作流程,其中两个点
1、Pose Matching使用的是部分骨骼点的物理属性:Local Velocity、Feet Positions、Feet Velocities、Weapon Position,Etc。
2、拟合Trajectory——未来的运动轨迹来计算Cost。
下面伪代码揭示了整个流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
int m_CurrentAnimIndex;
float m_CurrentAnimTime;
void AmoUpdate(Goal goal, float dt)
{
m_CurrentAnimTime += dt;
Pose currentPose = EvaluateLerpedPoseFromData(m_CurrentAnimIndex, m_CurrentAnimTime);
float bestCost = 1000000;
Pose bestPose;
// loop on all mocap
for (int i = 0; i < m_Poses.Size(); i++)
{
Pose candidatePose = m_Poses[i];
// every candidate jumping point has a cost
float thisCost = ComputeCost(currentPose, candidatePose, goal);
if (thisCost < bestCost)
{
// remember the best candidate
bestCost = thisCost;
bestPose = candidatePose;
}
}
bool theWinnerIsAtTheSameLocation =
m_CurrentAnimIndex == bestPose.m_AnimIndex &&
fabs(m_CurrentAnimTime - bestPose.m_AnimTime) < 0.2f;
if (!theWinnerIsAtTheSameLocation)
{
// blend to the winning location
m_CurrentAnimIndex = bestPose.m_AnimIndex;
m_CurrentAnimTime = bestPose.m_AnimTime;
PlayAnimStartingAtTime(m_CurrentAnimIndex, m_CurrentAnimTime, 0.25f);
}
}
float ComputeCost(Pose currentPose, Pose candidatePose, Goal goal)
{
float cost = 0.0f;
// how much the candidate jumping position matches the current situation
cost += ComputeCurrentCost(currentPose, candidatePose);
// this is our responsivity slider
static float responsivity = 1.0f;
// how much the candidate piece of motion matches the desired trajectory
cost += responsivity * ComputeFutureCost(candidatePose, goal);
return cost;
}

上图是使用额外的逻辑匹配:使用事件标记——作为额外的Cost计算,让代码逻辑希望能更期待的跳到预测的目标未来姿势并与当前姿势相匹配(如图Right Stance)。
演讲讲到轨迹模拟的两个选择概念——动画位移(Displacement from Animation)和动画模拟(Displacement from Simulation),就是Root Motion和引擎角色动画Motion的两个轨迹数据的选择。
- Displacement from Animation:
- 含义:Root motion完全由 MoCap 片段决定。轨迹直接取自动画数据。
- 优点:动作细节与惯性、步幅自然(演员真实移动)。
- 缺点:无法很好应对动态环境或玩家即时输入(例如突然避开障碍),需要大量手工修正或复杂的 warping。
- Displacement from Simulation:
- 含义:位移由游戏物理/控制器产生(如基于速度/力的模拟),动画需要跟随(retarget/IK)以匹配模拟。
- 优点:非常响应玩家输入、精确控制位置,可更好处理环境约束。
- 缺点:动画失去 MoCap 的自然细节,可能显得僵硬,需要额外调整去恢复真实感。
《For Honor》则使用的是不在这两者中“二选一”,而是让“代码决定真实的模拟点——也就是运行时用成本函数在动画数据库里选出最合适的候选点,然后切换/混合到那个动画时间点,从而兼顾真实感与响应性。具体工作方式:
- 系统保持当前播放的动画索引和时间(m_CurrentAnimIndex, m_CurrentAnimTime)。
- 每帧评估当前插值后的 Pose(EvaluateLerpedPoseFromData)。
- 遍历动画数据库中的候选“跳转点”(candidate poses / m_Poses),对每个候选点计算成本(ComputeCost),该成本结合:
- 当前匹配成本(ComputeCurrentCost):候选姿势与当前姿势、身体朝向、手臂/脚位置等的差异。
- 未来轨迹成本(ComputeFutureCost * responsivity):候选片段的未来位移轨迹与模拟期望轨迹(Goal)之间的偏差。responsivity 是滑块,用来权衡“更跟随模拟”或“更保留动画”。
- 选择成本最低的候选 bestPose(即最合适的“模拟点”)。
- 如果 bestPose 与当前动画时间/索引差异较大(不是“同一位置”),则混合到 bestPose。
- 同时新增弹性阻尼:速度三阶导数,让其跟有刚性效果。
未来轨迹预测也有各种有用的用处,其中一个就是碰撞预测。预测未来的运动轨迹,可以让动画做一些丝滑的墙角转弯。
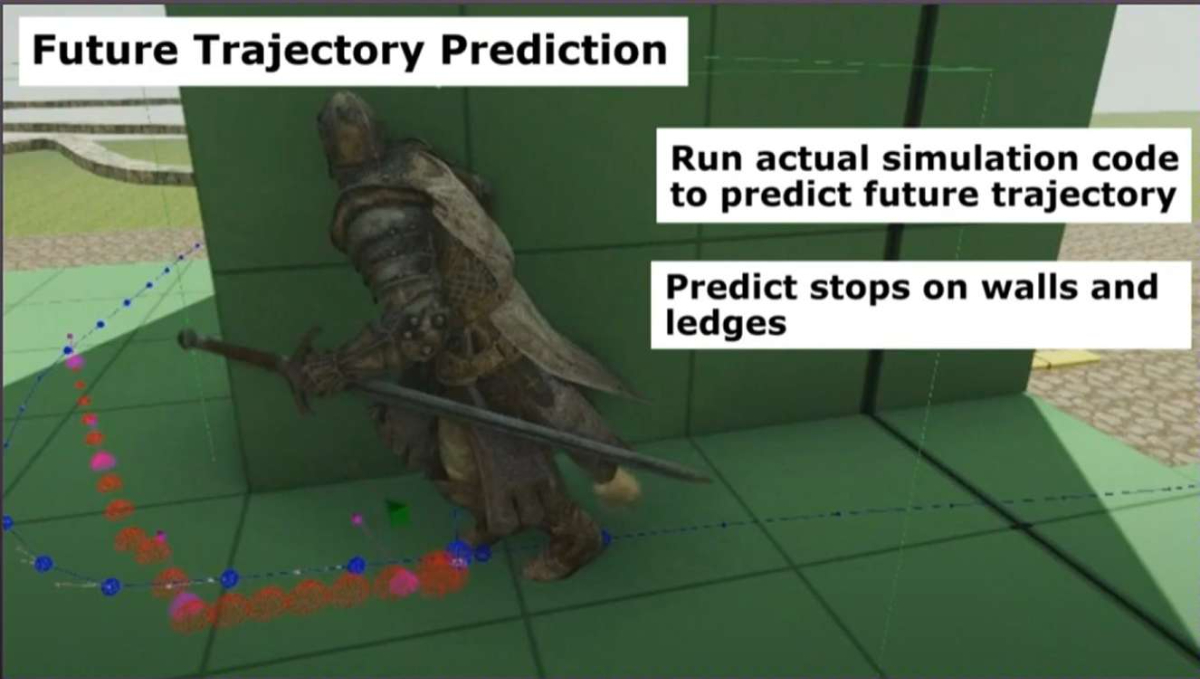
在每帧或在输入发生显著变化时,使用游戏里的运动/物理代码(移动控制器、物理引擎、碰撞检测等)做一个轻量级的前瞻性模拟(preview simulation),只模拟 root(根位置/速度/朝向等),不需要驱动骨骼动画。输入为当前角色状态(root pos/vel/orient)、当前玩家输入(目标方向、速度意图、跳跃/冲刺等)、环境碰撞体信息。输出为一系列时间采样的 root 位置/方向(例如 t = 0.1s, 0.3s, 0.6s …),形成 goal trajectory。其优点是结果反映游戏真实规则(摩擦、阻挡、坡度、跳跃规则等),用于后续成本比较更靠谱。墙壁若路径被障碍物阻挡,预测会显示速度衰减或沿墙滑动,最终在墙前停止,而不是穿透墙后继续。若将要掉下悬崖,预测器根据游戏规则(是否允许掉落/是否自动攀爬)决定继续或停止,从而避免选到会导致掉落的动画。这样 Motion Matching 在对候选片段进行未来位移匹配时,会把“穿墙/掉落”的候选片段打高成本,避免选择。

上图描述整个Mocap+Motion Matching的工作流:
1.离线阶段 — 动作捕获准备(Mocap is tweaked, imported, and marked up)。把原始 MoCap 数据清洗成可搜索、能用于实时匹配的数据库。
- 修复抖动、根位置(root)问题、去除丢帧。
- 标注事件(markup):脚触地(foot contacts)、手部抓取(hand contact)、attack frames、stance 等关键事件时间点。
- 产生索引数据:每帧存 root pos/rot、骨骼姿态向量、未来若干个 root 采样(用于 ComputeFutureCost)。
切割(可选):把长片段切为多个“跳转点”(jumping points / candidate poses),并记录 animIndex + animTime。
- 建议:存储时预计算特征向量(如关节位置归一化后拼接),便于在线快速比较;给每个候选点保存少量未来样本。
2.运行时:Gameplay 发出请求,通常包含:
- desired trajectory(期望轨迹):来自前瞻模拟(preview sim)或预测器,表示未来几时刻希望到达的位置/朝向。
- event constraints(事件约束):例如“在 t=0.4s 左脚必须着地”、“此时需要持盾”等。这些约束会影响匹配评分(被违反的约束应加大 cost)。
其他上下文:当前速度、姿态、武器状态、是否被击中等。
- Gameplay 层只负责“想要什么”,不直接操纵动画帧;动画系统负责把这些愿望转成实际播放的动画(或混合)。
3.动画系统:Pose/Trajectory/Event Matching(核心:Motion Matching)
- 每帧(或每 N 帧)执行:
- Evaluate 当前插值姿态(currentPose)以反映当前播放动画的视觉状态。
- 遍历候选点(或通过索引预筛选),对每个 candidate 计算成本:ComputeCost(currentPose, candidatePose, goal)。
- ComputeCurrentCost:衡量 candidate 与当前姿态/关节差异(避免突兀切换)。
- ComputeFutureCost(乘以 responsivity):衡量 candidate 的未来 root 轨迹与 desired trajectory 的差距(使动画响应玩家/物理)。
- ConstraintCost:事件约束违反惩罚(若 candidate 的某个关键事件时间不满足约束,加大成本)。
- 选最低 cost 的 bestPose:如果 bestPose 在时间/索引上与当前位置差距大,则触发切换(以 blend 混合过渡),否则继续当前播放。
- 优化手段:
- 先按粗特征(速度、方向、姿态类别)做桶化筛选,再在小集合中做精匹配。
- 用 KD-tree、PCA 或局部敏感哈希(LSH)来加速高维特征检索。
- 对 ComputeCost 进行向量化/SIMD 优化;或在 GPU 做并行评分(若数据量极大)。
4.后处理:Procedural Warping(把结果精确匹配到玩法与环境)
- 为了避免穿模、脚滑或与环境不符,需要对选中动画做微调:
- Two-Bone IK / Full-Body IK:对脚、手做位置修正以贴合地面或抓点。
- Motion Warping / Root Adjustment:调整根位移曲线来避免穿墙、修正转弯半径或保证手部能准确到达目标。
- Contact-Aware Corrections:在脚触地事件附近应用额外修正,保持足部贴地真实感。
(未完待续)